工作雜談:多餘的 DB 欄位跟關聯
最近在工作上遇到很困擾的事情之一,就是在資料的架構上,前人建了很多重複、多餘的關聯跟欄位。
多餘的關聯
例如系統中有很多使用者(users),每個使用者一定會屬於一間店家(stores),但這些店家之間不會共用使用者資料,使用者上會有 store_id 欄位去紀錄這個多對一的關聯。
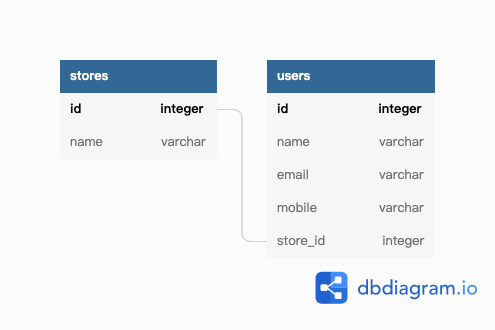
接者,每個使用者都有他綁定的支付方式(payment_methods),一個支付方式只屬於一位使用者,沒有共用的狀況。支付方式上會有 user_id 紀錄他屬於哪一個使用者。
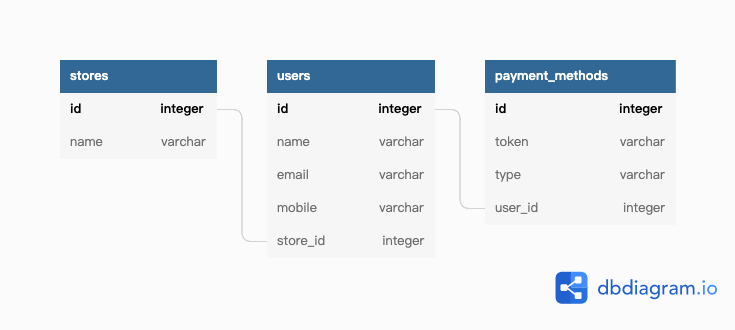
如果今天我想在支付方式列表上看見這是哪個店家底下的支付方式,我應該會從支付方式找到關聯的使用者,再找到所屬的店家。但前人可能覺得「一直 JOIN 好麻煩哪」之類的,於是錢包上也多了一個 store_id 去紀錄關聯到的店家。
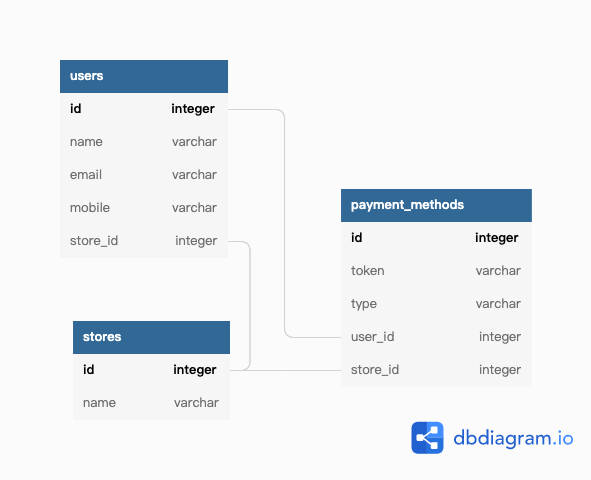
整個資料庫多了好幾條關聯看起來都是為了少幾條 JOIN 建的,卻搞得撈資料的人不知道多個來源到底哪一個才是對的。這個時候如果錢包的 store_id 跟所屬 user 身上的 store_id 不同的時候,就會相當懊惱我到底該相信誰。
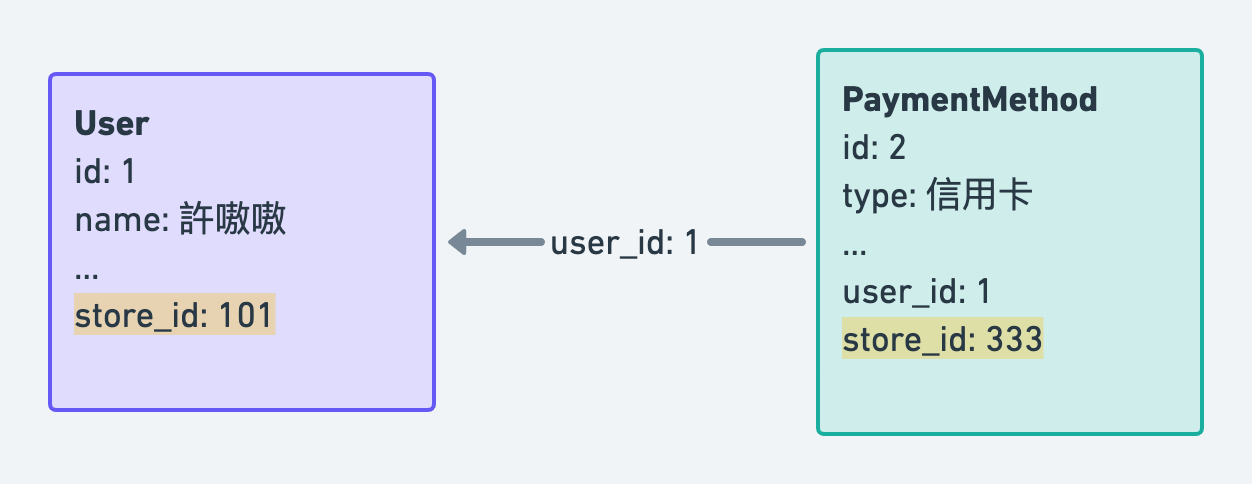
多餘的欄位
舉例來說,訂單(orders)底下會有很多刷卡紀錄(payments)。例如訂單有可能刷卡失敗,最後終於刷成功時,整張訂單才算是付款成功了。
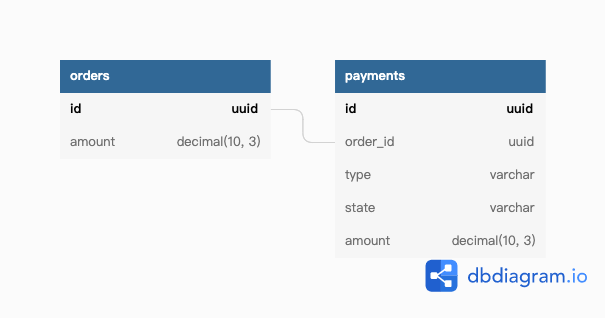
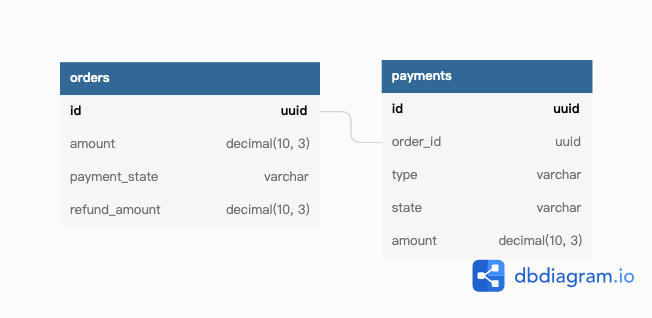
或者是,訂單可能會有退款紀錄,可能部分退款,也可能是全額退款。可能退款 10 元,也可能退款 20 元。訂單上有付款狀態(payment_state)、退款金額(refund_amount)這樣的欄位在紀錄付款結果、退款金額。
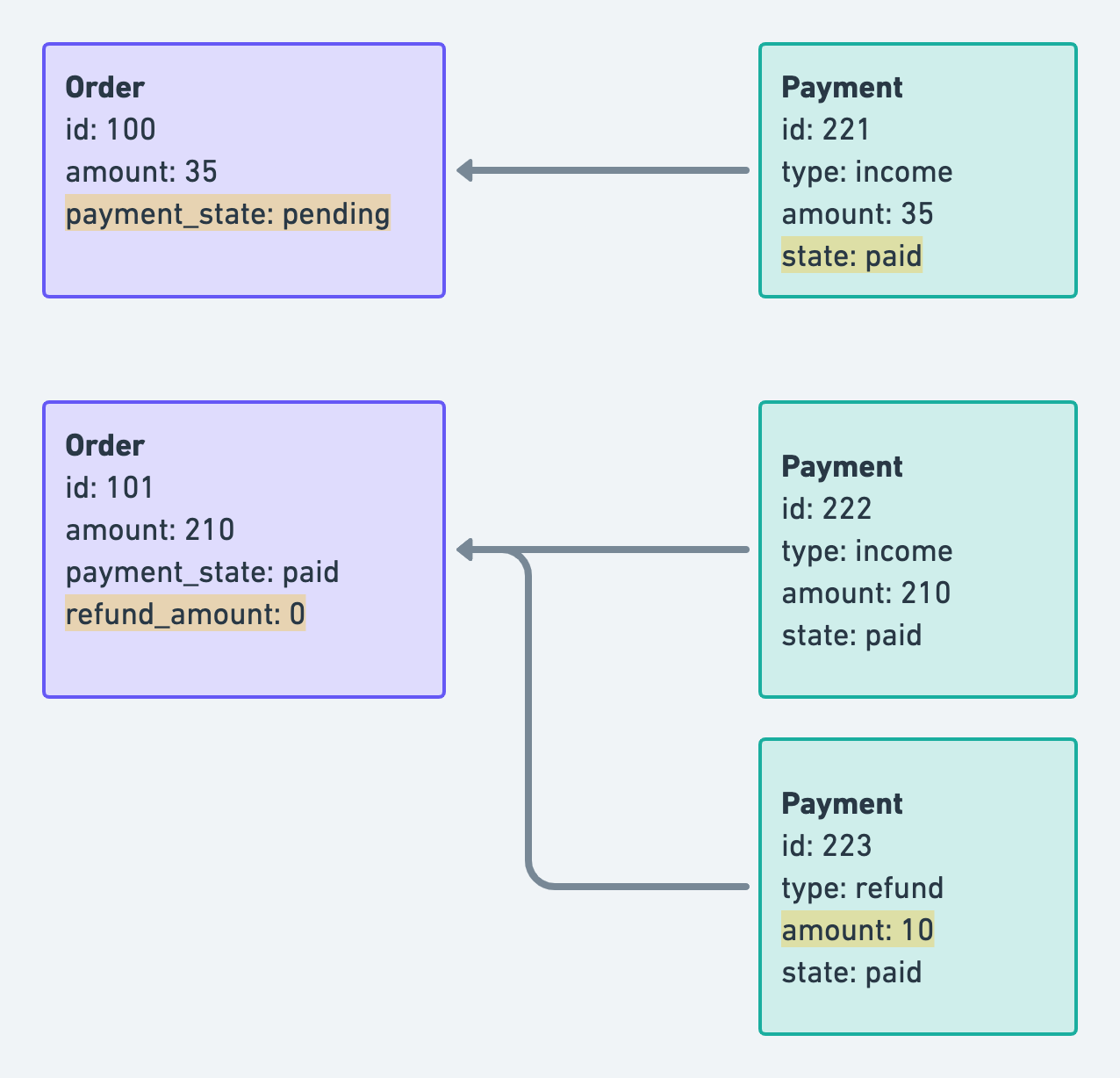
原本另開欄位可能是圖個方便直接拿欄位的數值來使用,但當 code 寫爛了的時候,就會發生一些狀態不一致,不知道哪個欄位才是正確的問題。例如,當付款狀態(payment_state)是的「訂單等待付款(pending)」,但訂單卻有付款成功的紀錄時,我應該相信誰?如果訂單有一筆成功退 10 元的退款紀錄,但這筆訂單的退款金額(refund_amount)卻還是 0 的時候,是不是我拿訂單的退款金額(refund_amount)去做後續的判斷跟分析時,會大錯特錯?
Single Source of Truth
關於以上的例子,第一個想要談談的概念是 Single Source of Truth。單一事實來源(Single Source of Truth,SSOT)大致上的意思是說,資料應該要由同一個來源讀取跟計算數值。
在以上讓我困擾的例子中,很大的問題是我會有兩個以上的 data source,讓我不知道應該要依循哪一個。如果今天寫 SQL 時是用 A 來源,同事卻是用 B 來源,有可能資料不一致時會帶來錯誤跟困擾。
Event Sourcing
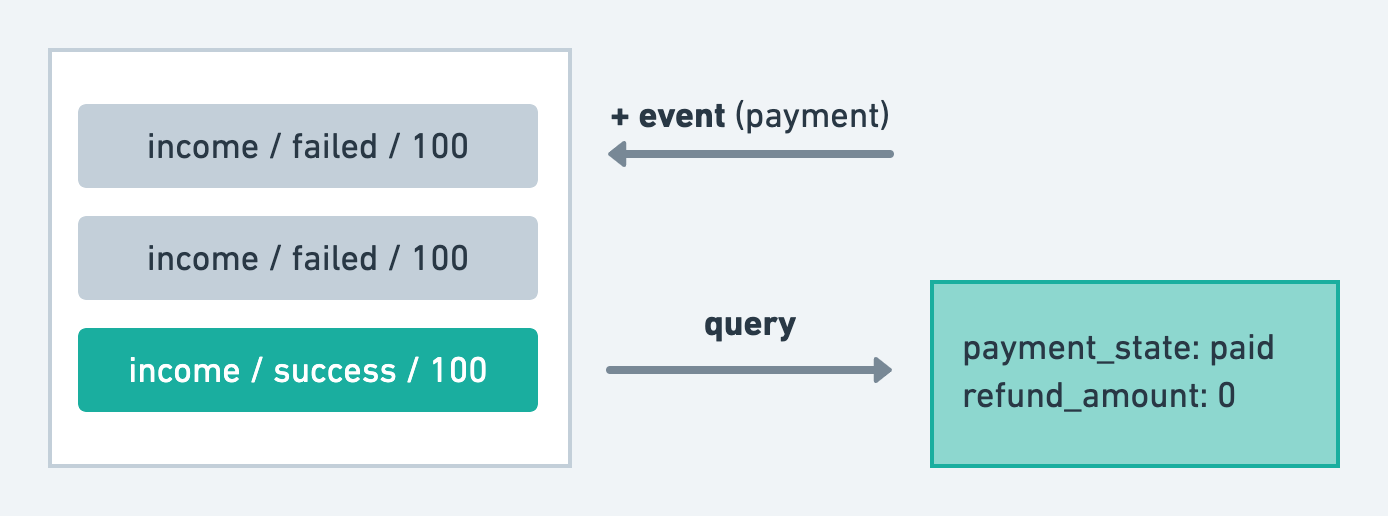
再來看看付款紀錄的例子,其實,付款狀態可以用這張訂單的「付款紀錄」的狀態去獲得,例如:
- 有付款成功的付款紀錄 => 訂單付款成功
- 沒有任何付款紀錄 => 訂單等待付款
- 有付款紀錄但沒有付款成功的 payment => 訂單付款過但失敗了
退款金額在可以直接用訂單底下的退款紀錄去得到目前退過多少錢,把退款成功的退款紀錄的金額加總,就會是目前退款的金額。
我覺得會是用類似 event sourcing 的方式來得到訂單的付款狀態跟資訊,每個付款紀錄、退款紀錄其實相當於一個個 event,將這些 event aggregate 起來,我就可以拿到當前訂單的狀態。
performance
我覺得前人的架構之所以會設計成這樣,可能是有 SQL 效能上的迷思。例如,如果把一些需要 JOIN 兩次以上的關聯變成 JOIN 一次就好,是不是就可以讓 SQL 效能變好了?或者是原本需要關聯到 payments 去看付款狀態跟退款金額的方式需要 JOIN payments 這張表,如果把我要的資訊放在 orders 的欄位上是不是可以少一個 JOIN 造成的負擔?
但我自己覺得這會是很大的效能迷思。首先,如果 JOIN 了資料,下了 WHERE,結果資料撈很久,應該先 EXPLAIN 一下,看看 SQL 到底慢在哪裡。常常很大一部分都是沒有 index,沒吃到 index 造成的問題。沒有吃到 index 的時候,資料庫可能會用逐行掃描的方式 seq scan 過整張表去找資料,
-> Seq Scan on orders (cost=0.00..504250.77 rows=11831677 width=267)
加好了 index 以後,如果撈取資料時有正常吃到 index,會使用 index scan 的方式去撈資料。在資料量大的時候,效能的差異會有很明顯的差別。我會覺得如果覺得 JOIN 表時, SQL 就變得好慢,應該先檢查一下 foreign key 跟 WHERE 使用的欄位有沒有好好的下到 index。
-> Index Scan using index_payments_on_order_id on payments (cost=0.43..5.80 rows=1 width=1376)
Index Cond: (order_id = orders.id)
在 DB 的架構設計上,我覺得真的是特別需要深思熟慮的事情,後續要再盤點欄位的意義、被如何使用,甚至要想試著進行搬移整併的話都會相當困難QQ
